mirror of
https://github.com/healthchecks/healthchecks.git
synced 2026-04-25 23:15:49 +03:00
[GH-ISSUE #547] Healthcheck with Started and OK pings goes down if OK hasn't come at one grace period after Started #395
Labels
No labels
bug
bug
bug
feature
good-first-issue
new integration
pull-request
question
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/healthchecks#395
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @kaysond on GitHub (Jul 28, 2021).
Original GitHub issue: https://github.com/healthchecks/healthchecks/issues/547
I have a check with a 1 week period and 6 hour grace time. It's a very long
borgmatic checkoperation. As you can see below, itStartedat 5am, and at 11am (6 hours later) the check went down because the grace period had elapsed.This doesn't seem like accurate behavior to me. The operation just isn't done, that doesn't mean it's down.
If I had a check without a
Startedping, it would just compare to theOKtimes, and only if theOKcame > 1 period + 1 grace period after the previousOKwould it go down.Sorry if my description is confusing... I can try to clarify further.
@cuu508 commented on GitHub (Jul 28, 2021):
Hi @kaysond, this is the intended behavior, and it is mentioned in the documentation:
I would recommend to estimate the maximum time
borgmatic checkcan be expected to take, and adjust the grace time to be a bit above that.@kaysond commented on GitHub (Jul 28, 2021):
If your intention is to track expected run-time, I think it would be much better to have a separate control for that. It seems bad to link the grace period to expected run-time.
Consider a cron job that runs once a week on Sundays, and takes about 1 day to run. Based on what you've said, I would have to set grace period to >1 day. But its a cron job so it should start at the exact same time every Sunday. Ideally I'd want the grace period to be 1hr or less. Having to wait until the next day to get a down notification just because the job takes a long time is a bad thing.
Thoughts?
@cuu508 commented on GitHub (Jul 29, 2021):
Grace period is the expected run-time.
Consider the case where a job is scheduled using a cron expression and does not make use of the
/startsignal (the job only sends the success signal when it completes). The cron expression tells when the job is expected to kick off. The grace time tells how long the job is expected to take. So if there is no ping after kickoff time + grace time, the job goes down.Now consider the case where a job does send the
/startsignal. The start signal tells when the job kicks off. The grace time tells how long the job is expected to take. If the time since/startexceeds grace time, the job goes down.I think I understand your problem though. You need a timely alert if a job fails to start, and another alert if it fails to finish 24h or so later. Adding additional configuration options or a rule system could work, but there's a tradeoff between the flexibility and the ease of use. Very long running cron jobs are not common, and the existing implementation works well enough for typical durations (seconds to hours).
Here's one idea – you could track the start and the completion using two separate checks:
Now, if the cron job doesn't start at all, you will get alerted within a minute by "borgmatic check has started". And if it does not complete in 1 day, you will get alerted by "borgmatic check has finished".
How does that sound?
@kaysond commented on GitHub (Jul 30, 2021):
Ah I see where the confusion is coming from, and part of it is just documentation - I'm using the simple schedule mode. In this case, I correctly expected "grace time" to mean how much time
healthcheckswaits after a "period" elapses before marking the job as down. This makes sense because you generally expect the ping exactly once every period, but job times can vary.This is what caused my confusion. It's called "grace time", and for simple schedule mode, it is actually a "grace" time. For a cron schedule or
/startsignal, though, you're using it as an expected runtime. Semantically, thats not what I understand to be a "grace" time. "Grace" time to me usually means in addition to a deadline or expectation.So you're essentially assuming a 0-length run time for a job, with a potentially very long grace time. This was not immediately clear to me because of the language as mentioned above.
To be honest, I didn't read the documentation for
/startsignals, and that's obviously my own fault.borgmatichas built-in support forhealthchecks, so I figured I could just give it a url and it would just work.FYI - based on the simple schedule mode in the interface (i.e. "period" and "grace time" explanations), I incorrectly assumed that the
/startsignal was just used to time the duration of the job, and thathealthcheckswas comparingoksignal to previousoksignal, just as in normal simple mode.Some context, if you're not familiar:
borgmaticis a backup configuration tool that runsborg-backupusing job definitions in various yml files. Because aborgrepo can only create one archive at a time, some backup jobs must run sequentially. Also,borgmaticpings onehealthcheckurl per yml file.This means that even though I have a cron job set to start the whole process, I can't be sure of when each individual job starts. This is a common scenario for backups. My veeam setup works the same way. Additionally, since my
borgmaticjobs are in different files (for different source directories, compression requirements, etc), each job must ping its own url. So I have to use simple mode, andborgmaticwill send astartandokping. It's slightly further complicated by the fact that incremental backups run fairly quickly, but the periodic full backups are much slower.Agreed!
I don't think this is accurate. Backup jobs can be very long, especially offsite ones over the internet.
Sure. It does work well enough. But I think it would be better all around if
healthcheckswere "smarter" and tracked both the start time and end time of jobs.Definitely a possibility (I think
borgmaticsupports arbitrary scripts pre- and post-backup), but then I substantially increase the complexity of the setup. I also lose the job duration tracking which is rather nice.I realize this got somewhat long, so if you made it this far... thanks! I'm hoping you'll consider 1) improved clarity in the documentation language and UI language, and 2) more advanced behavior for simple scheduling with
startpings (or an enhancement that addresses the same issue, like separate job duration and grace time)@cuu508 commented on GitHub (Aug 3, 2021):
Thanks for the extra explanation and details!
Yes, happy to improve documentation. Do you have specific suggestions?
I suppose in https://healthchecks.io/docs/measuring_script_run_time/ this lone paragraph could be expanded, it is easy to miss.:
Signaling a start kicks off a separate timer: the job now must signal a success within its configured "Grace Time," or it will get marked as "down."
I still think the flexibility / complexity tradeoff is not worth it. I had a quick look at production data – the percentage of checks with the last execution time > 24 hours is 0.03%.
@kaysond commented on GitHub (Aug 3, 2021):
Yes, definitely there. Also in https://healthchecks.io/docs/configuring_checks/, under
Simple Schedules, I think it would be helpful to add a note on how the behavior of "Period"/"Grace Time" changes if your job sends a/startping.Also it would probably be good to include a note about period/grace time when measuring runtime, on the Simple Schedule UI itself, which currently has very simple descriptions. Probably in the check details page as well:
So I just checked and my longest backup jobs are 12-15hrs, but most are 1-6hrs. Out of curiosity, what percentage of checks do you have > 6hrs? > 12hrs?
@kaysond commented on GitHub (Aug 3, 2021):
Also - if you do use a simple schedule, and the job pings
/start, doeshealthchecksjust ignore theperiod?@cuu508 commented on GitHub (Aug 6, 2021):
I'm looking into improving the documentation, but every sentence is a struggle – as always :-/
No, the normal rules still apply. But, let's say, if you set period to 30 days, you would have almost that. In that case, the job is free to start "whenever", but when it starts, it must complete within grace time. And it needs to complete at least once every 30 days.
@cuu508 commented on GitHub (Aug 10, 2021):
On Healthchecks.io,
@kaysond commented on GitHub (Aug 10, 2021):
I'm assuming the grace time still applies to the period? Meaning, suppose I have a 6hr daily job. I set the period = 1 day, and grace time = 6hr. It starts Tuesday at 5am and finishes at 11am. The next day, Wednesday, its delayed for some reason and starts at 10:59am. It still wouldn't mark it as down because the grace time hasn't elapsed, correct?
That's really interesting. I guess there aren't a lot of off-site backups over slow connections 😄
@cuu508 commented on GitHub (Aug 11, 2021):
Yes.
The run on Tuesday completes at 11am. On Wednesday, at 10:59, it has not yet exceeded its period of 1 day (one minute of time is still left), so its status will be "up" (green checkmark icon).
Let's say there is no "success" ping at all on Wednesday. Here's what would happen next:
Now, for the sake of example, let's add a "start" signal in the mix:
@kaysond commented on GitHub (Aug 12, 2021):
Thanks for the explanation. This is helping my understanding but also highlighting why I was confused!
So in the second case (i.e. with "start"), does the check go late/down if "start" takes too long?
@cuu508 commented on GitHub (Aug 12, 2021):
No, "start" signals are optional. All that matters is that "success" signals arrive on schedule. But if you do send start signals, the schedule has one extra rule: gaps between "start" and "success" signals must be < grace time.
PS. I've updated documentation in a couple places:
You also suggested updating wording in the Period / Grace dialog, and in the Check Details page but I think multi-sentence descriptions would not fit there.
@kaysond commented on GitHub (Aug 12, 2021):
That's much clearer. Thanks.
I agree, but I bet you could do a single sentence that explains the additional rule. Maybe something like:
Grace Time how long to wait after a check is late, or after a start signal is received, to send an alert
Ah. So I thought the
startsignal makes sure the job starts on time, in addition to measuring run time. That's something that would be desirable for the 1% of us that run long jobs, since you could get an earlier alert if the job doesn't even start.@kaysond commented on GitHub (Aug 12, 2021):
I wonder if a clean way to add some flexibility, without over-complicating the UI, is to add a couple of "advanced" checkbox options under the Schedule section of the check page. This way it doesn't clutter the regular schedule modal, and on launch, no default behavior changes.
[X] Send an alert if the job doesn't finish within a grace time of the start
^default on, behavior while on is unchanged from current behavior. when off, it disables the extra rule that monitors the gap between start and success. there is still the normal "success" rule that will trip if the time between success pings is too long
[ ] Send an alert if the job starts late
^ default off. if on, adds "success"-like monitoring to the "start" that brings it down after 1 period + 1 grace time after the last start
@cuu508 commented on GitHub (Aug 18, 2021):
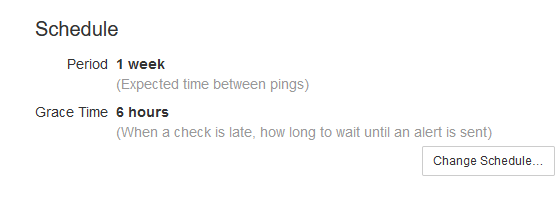
That's good point, I've updated the "Change Schedule" dialog:
The scheduling options logically belong together. Having some inside the modal, and a few others outside it does not make sense to me. But we could probably find or make a place to tuck the additional configuration options in. There would still be the task of documenting these options, and actually implementing them.
I'll leave this as-is for now.
@kaysond commented on GitHub (Aug 19, 2021):
Nice!
Good point. I agree.
I think so too, and understand that its not necessarily a simple task.
That's disappointing. I think healthchecks would be more useful and more powerful if grace time and job run time were separated. Just because most checks are short doesn't mean those checks wouldn't use the extra functionality.
Nonetheless, I appreciate your willingness to discuss it.
@ilanbenb commented on GitHub (Sep 19, 2021):
Hey,
when a check is late, OR has recieved aI would advise putting the "or" word in bold underlined font to make it crystal clear :)
@cuu508 commented on GitHub (Sep 20, 2021):
Thanks for the tip, @ilanbenb.
I made "or" bold. I didn't add the underline, I think could be confused with a link then.