mirror of
https://github.com/RD17/ambar.git
synced 2026-04-25 15:35:49 +03:00
[GH-ISSUE #258] Tesseract working out only the first five pages of documents #247
Labels
No labels
$$ Paid Support
bug
bug
enhancement
help wanted
invalid
pull-request
question
question
wontfix
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/ambar#247
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @santangelo on GitHub (Aug 21, 2019).
Original GitHub issue: https://github.com/RD17/ambar/issues/258
Hi,
first of all thank you for this great work you did.
I have set up Ambar to crawl a number of pdfs in an Archive folder with subfolders containing pdfs.
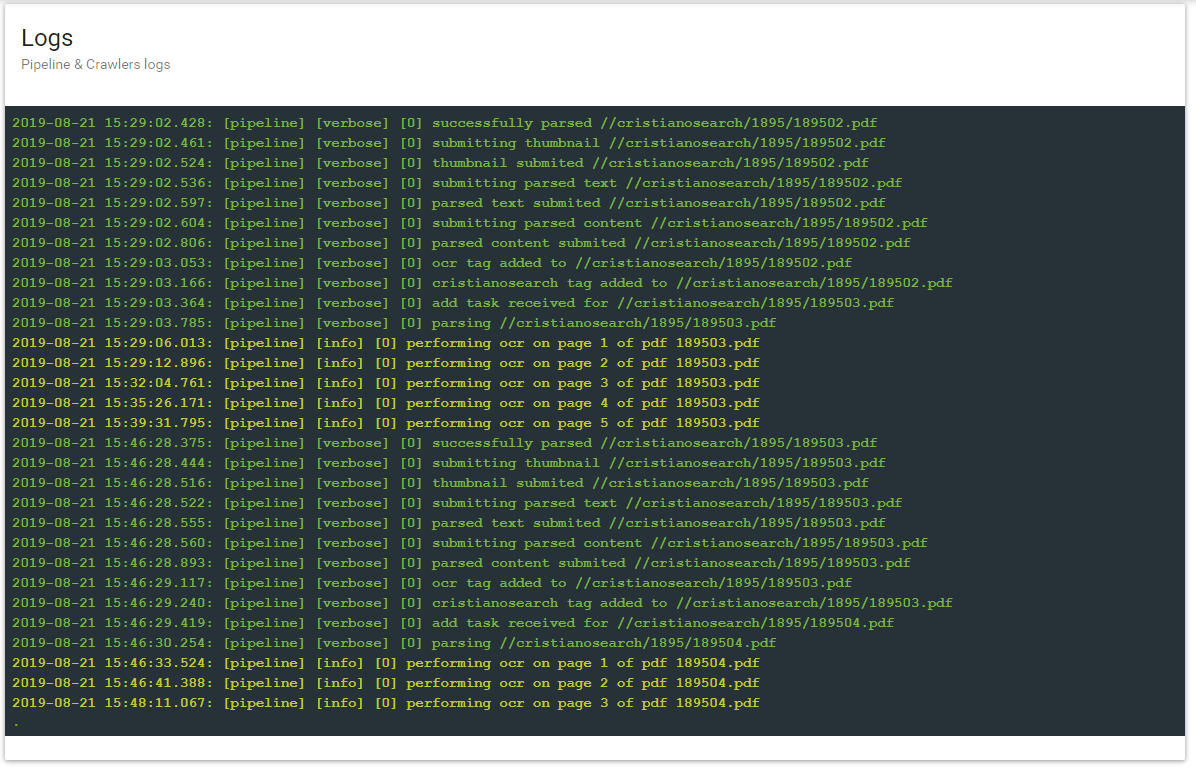
It seemed to me that it was doing great, but I have just noticed in the crawler log that Tesseract is processing only the first five pages of the documents (attached screenshot).
Of course the words from the 6th page on are not in the index.
Is there an option I did not know of?
Thanks a lot.
Michele
@santangelo commented on GitHub (Aug 22, 2019):
In case it helps other, it was enough to set the env var "ocrPdfMaxPageCount" to desired number of pages on pipeline container. Thanks to the Ambar help.
Michele