mirror of
https://github.com/hibiken/asynq.git
synced 2026-04-26 07:25:56 +03:00
[GH-ISSUE #286] [BUG] The task is always active #1129
Labels
No labels
CLI
bug
designing
documentation
duplicate
enhancement
good first issue
good first issue
help wanted
idea
invalid
investigate
needs-more-info
performance
pr-welcome
pull-request
question
wontfix
work in progress
work in progress
work-around-available
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/asynq#1129
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @GoneGo1ng on GitHub (Jun 29, 2021).
Original GitHub issue: https://github.com/hibiken/asynq/issues/286
Originally assigned to: @hibiken on GitHub.
Describe the bug
When the task is active, the worker shutdown, then the task will always be active.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
I think the task should change the state to failed based on Timeout, MaxRetry, etc.
Screenshots
If applicable, add screenshots to help explain your problem.
Environment (please complete the following information):
asynqpackage: v0.17.2@crossworth commented on GitHub (Jun 29, 2021):
Hello, are you sure that the task is not recovered after 1 minute?
On pull request https://github.com/hibiken/asynq/pull/181 was added support for task recovery on worker crash.
The way the crash recovery works it's quite simple, on server (worker) startup after 1 minute
github.com/hibiken/asynq@2516c4baba/server.go (L376)A routine is executed to list all the "DeadlineExceeded" tasks:
github.com/hibiken/asynq@2516c4baba/recoverer.go (L70)And the retry/archive is executed based on the task Retry/Retried value:
github.com/hibiken/asynq@2516c4baba/recoverer.go (L77-L81)if the task should be retried, a delay function is used as well:
github.com/hibiken/asynq@2516c4baba/recoverer.go (L89-L95)the default delay function used is this:
github.com/hibiken/asynq@2516c4baba/server.go (L261-L268)If you don't provide a timeout and deadline the default 30 minutes timeout will be used.
github.com/hibiken/asynq@63ce9ed0f9/client.go (L238)NOTE: if you set
asynq.MaxRetry(0)when usingEnqueueand the worker crash, no retry will be executed.The recovery only works when you start the worker, so if are inspecting the redis directly you will not see the task been recovered unless you start the server (worker).
@GoneGo1ng commented on GitHub (Jun 29, 2021):
This is my worker, I mean, I shutdown it. I'm pretty sure it didn't recover or retry. It's been more than two hours now.
@hibiken commented on GitHub (Jun 29, 2021):
@GoneGo1ng Thank you for opening this bug!
@crossworth thank you for helping out here!
Can you provide what you are seeing in your logs on Server shutdown?
As documented in this wiki, you should send a TERM signal to the server process to shutdown the server. Upon receiving a TERM signal, the server waits for duration specified by
ShutdownTimeoutfield (https://github.com/hibiken/asynq/blob/master/server.go#L127) and pushes back any tasks that didn't complete within that window (the tasks will be in pending state after pushed back).As @crossworth mentioned, if worker didn't get to push back the task (e.g. worker crashed, or killed by KILL signal) then tasks will be recovered on server restart.
@GoneGo1ng commented on GitHub (Jun 30, 2021):
Thank you for reminding me. I didn't read the document carefully. TERM signal gracefully shut down background process.
@thanhps42 commented on GitHub (Jun 30, 2021):
@hibiken
Sometimes we can't send a TERM signal to server process. I run worker process in my laptop, but I the worker maybe exit unexpected (such as: windows auto update, electric-power-off,...). I was set the timeout for task, but it never fire.
P/s: sorry for my English.
@hibiken commented on GitHub (Jun 30, 2021):
@thanhps42 thanks for the question.
Like @crossworth mentioned in the comment, deadline exceeded tasks (i.e. timed out tasks) are recovered when you restart the server. If you run multiple worker servers, it may help to minimize the time before the timed out tasks get recovered.
For example:
Let me know if you have questions on this.
@thanhps42 commented on GitHub (Jul 2, 2021):
I was set deadline for Task1, but it never get timeout. No deadline exceeded even Timeout was set.
@crossworth commented on GitHub (Jul 2, 2021):
@thanhps42 could you describe the exact process you are doing to test this behaviour?
Are you sure that the worker is running?
The recovery process will not happen if the worker is stopped.
If I create a task with timeout of 1 minute , enqueue it, the worker starts processing it but crashes, the task will be in Active state until I start the worker again.
@thanhps42 commented on GitHub (Jul 2, 2021):
@crossworth
When I start the worker again, it process new pending task, these old active task still stay there (and "Started" status always "just now").
@hibiken commented on GitHub (Jul 2, 2021):
@thanhps42 Thank you for reporting this!
@crossworth thank you for following up to this issue!
I can reproduce this bug, and it seems like
RDB.ListDeadlineExceededis not returning the deadline exceeded messages.I'll look into this bug in the next few days, but feel free to open a PR for the bug fix if anyone else is interested in this.
@hibiken commented on GitHub (Jul 2, 2021):
Sorry, I take it back!
It's working as intended, but I overlooked that by default tasks' timeout is set to 30mins.
@thanhps42 I'm suspecting you are encountering the same thing.
From the screenshot you provided, it seems that you are setting the task timeout to 20mins. So the abandoned active tasks are not going to be recovered until they hit their deadline (which is set to
time.Now() + task.Timeout). So after 20mins or so if you have a server running, those active tasks will be recovered and put back in pending state.I'll close this bug, but please let me know if you have any questions!
@thanhps42 commented on GitHub (Jul 2, 2021):
@hibiken The task timeout is 20mins. After many hours, 1 task is recover, and 1 task still there?
@hibiken commented on GitHub (Jul 3, 2021):
That's strange.
Would you mind running this command and paste provide the output here?
redis-cli zrange asynq:{<qname>}:deadlines 0 -1 withscores(where<qname>is your queue name)Also, did you recently migrate from Asynq v0.17 to v0.18?
@thanhps42 commented on GitHub (Jul 3, 2021):
I was pause the queue 1 hour ago, the task still there.
My asynq version is v0.17.2. I have no update/migrate.
@hibiken commented on GitHub (Jul 3, 2021):
Would you mind running:
and paste in the output here?
@thanhps42 commented on GitHub (Jul 4, 2021):
P/s: sorry for my delay
@thanhps42 commented on GitHub (Jul 4, 2021):
#client:
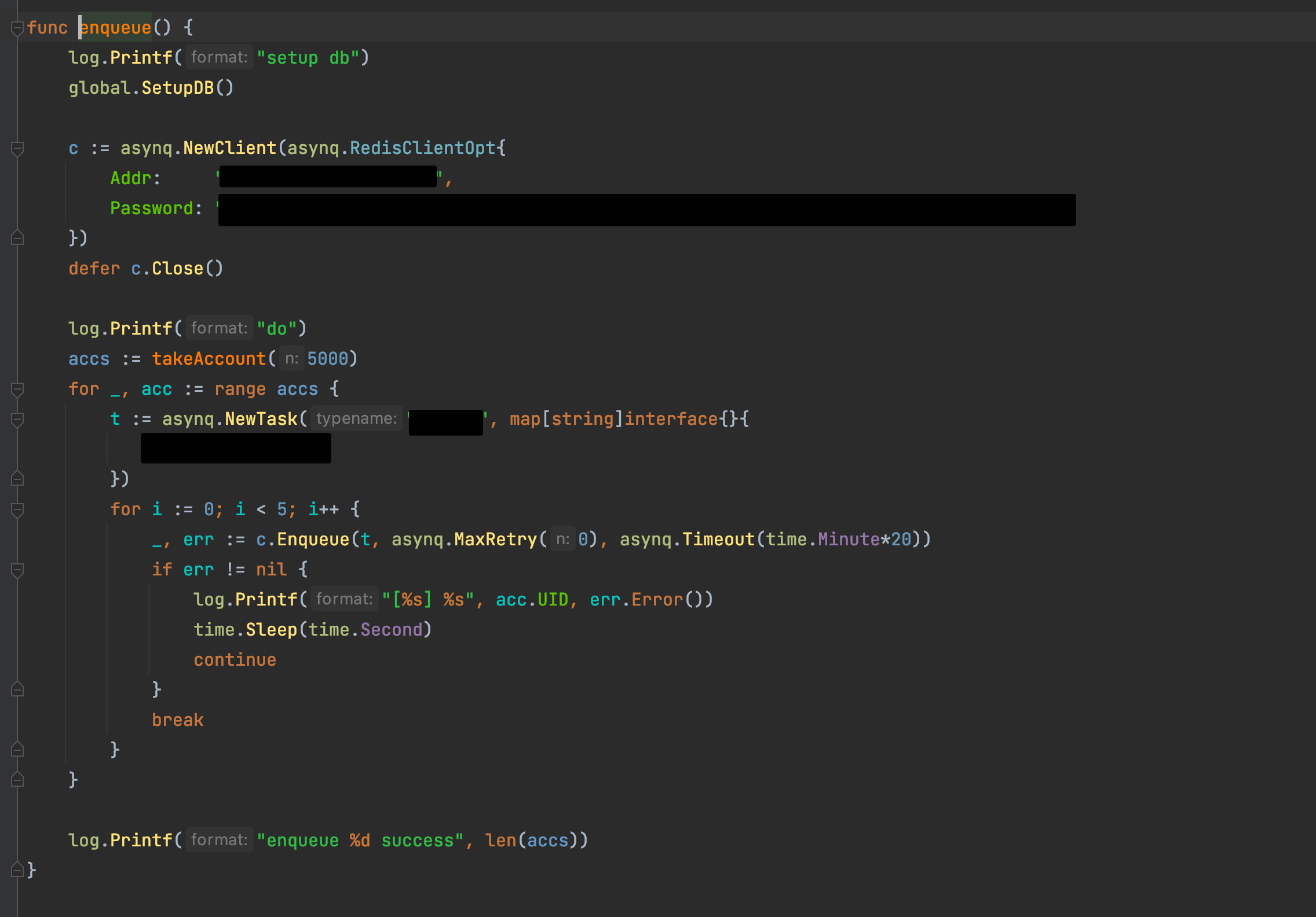
@hibiken commented on GitHub (Jul 4, 2021):
Ok that seems normal to me. Thank you for providing the info.
Would you mind running the server and keep it running for at least one minute? (You need to keep it running for one minute since current implementation only execute task-recovering logic every minute).
If recoverer is failing, you'll see some warning logs like these:
https://github.com/hibiken/asynq/blob/master/recoverer.go#L72
https://github.com/hibiken/asynq/blob/master/recoverer.go#L93
https://github.com/hibiken/asynq/blob/master/recoverer.go#L99
Please let me know what you see in your logs :)
@thanhps42 commented on GitHub (Jul 4, 2021):
After start and stop the worker many times, the active task was gone. I don't know why.
@crossworth commented on GitHub (Jul 4, 2021):
@hibiken I would like to clarify something, you said "task-recovering logic every minute", but a
Timer.NewTimeris used, this means that it only happens one time: https://golang.org/pkg/time/#TimerIs this the default behaviour, or was intended to execute every minute, if so maybe is better to use a
time.NewTicker: https://golang.org/pkg/time/#Ticker or callresetlike onhealthcheck.goandheartbeat.go.@hibiken commented on GitHub (Jul 4, 2021):
@thanhps42 Even though we couldn't get to the bottom of this, this was a good opportunity to take another look at task recovering logic, so thank you 🙏 And please let me know if you see the issue again.
@crossworth Thank you for spotting! Yes, we should call
Timer.Resetin recoverer. My reasoning behind using theTimerinstead ofTickeris because I wanted to ensure that we start counting after the current execution is done. See the example below.But I'm open to suggestions. Let me know if you have thoughts on this!
@crossworth commented on GitHub (Jul 4, 2021):
I see, thats makes sense, I think a Timer is a better solution for this case.