mirror of
https://github.com/cbeuw/Cloak.git
synced 2026-04-25 12:35:59 +03:00
[GH-ISSUE #74] Random unable make connection through the cloak #65
Labels
No labels
pull-request
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/Cloak#65
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @chenshaoju on GitHub (Nov 5, 2019).
Original GitHub issue: https://github.com/cbeuw/Cloak/issues/74
Sorry for my English.
Server: Debian 10 x64 (shadowsocks-libev 3.2.5)
Client: Windows 7 x64 (shadowsocks-windows 4.1.8.0)
Cloak Version: Build from source (commits 293)
I notice there is a random issue when used with shadowsocks.
Sometimes, Client requests through the local proxy randomly timeout or unable connection to the target server, For firefox is "The connection has timed out" or "Secure Connection Failed",if refresh page 1~2 times will working again.
In my using environment, aways has active connections, maybe there is some request conflict or something else?
Here is a screenshot from curl:
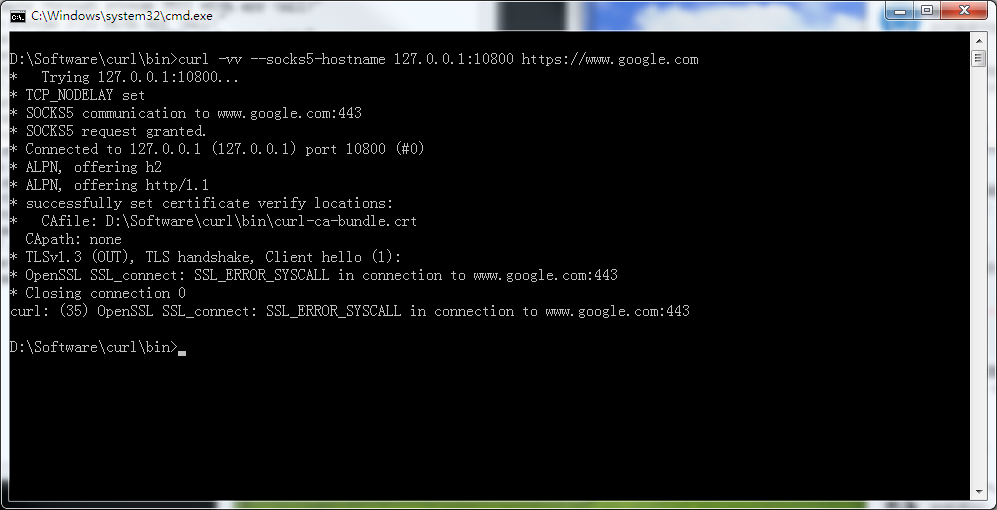
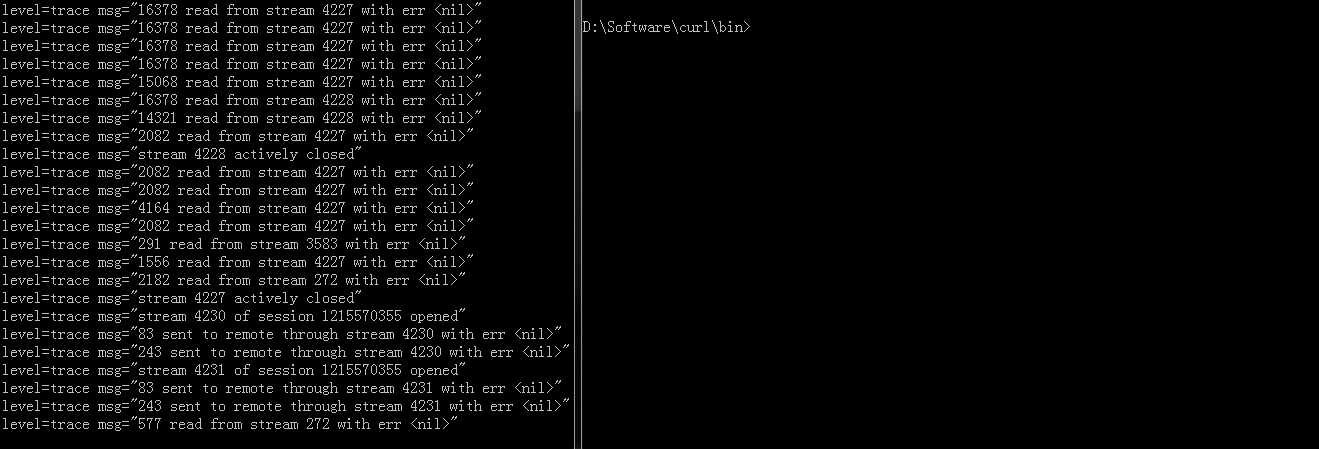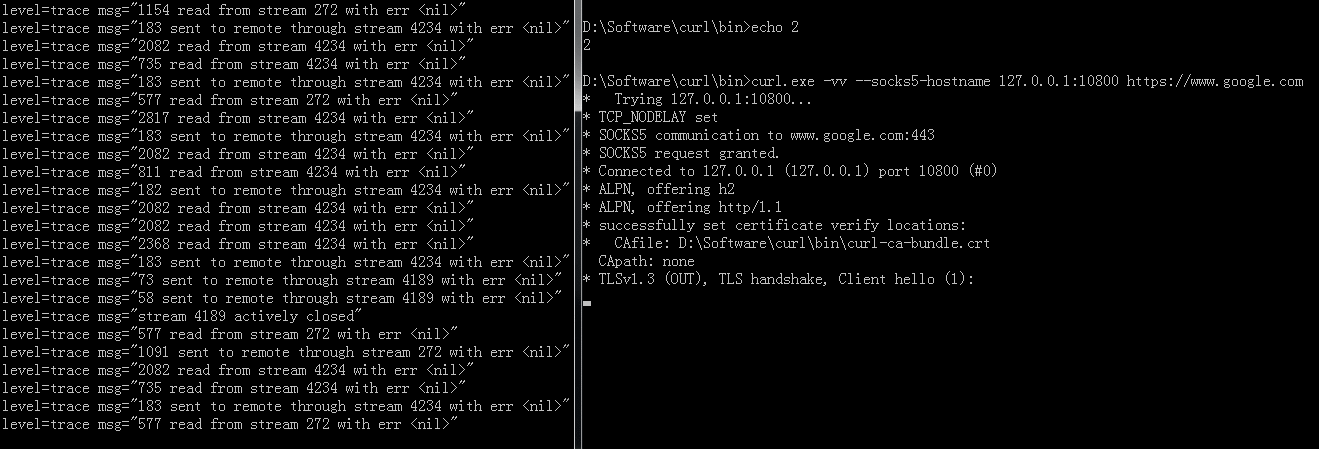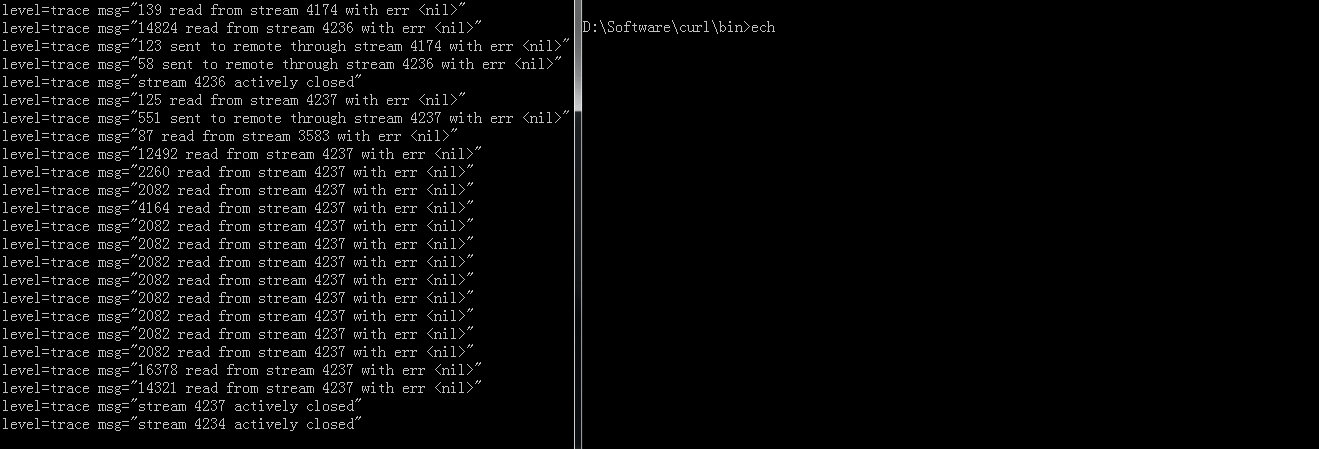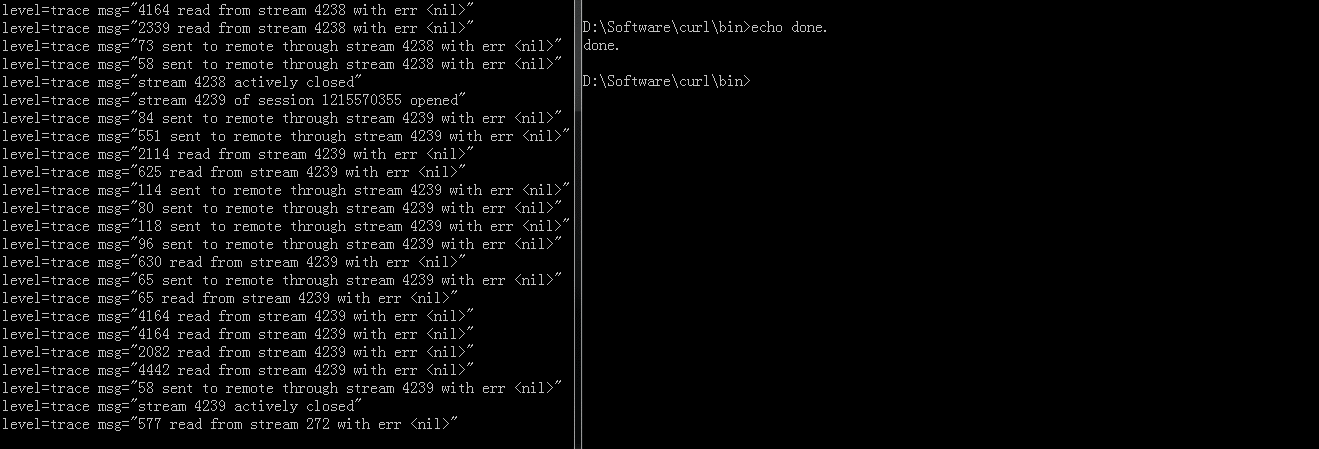
Here is log with the screenshot:
PS: maybe from
Start heretoEnd hereis curl requesting.Here is a GIF demo when the issue happened(Click for zoom):
Server configure:
Client configure:
PS: I try increase
NumConnto 12,But unable solve this issue.If need any information, please feel free to ask.
Thank you.
@notsure2 commented on GitHub (Dec 11, 2019):
@cbeuw
I am also facing this problem. It is easy to trigger it. Set NumConn = 1 and then start and cancel wget on a large file many times. With trace logging I see that the bytes are sent but then no response is ever received by the client and the connection stalls. With the server also on trace logging, I can see that the server read the bytes sent by the client and sent 2 responses, but the client doesn't process the response and hangs. Maybe it is a problem of buffer flushing ? or goroutine starvation ? (noob at go, forgive me if I am mistaken, just throwing an idea).
When this condition happens it seems the entire session hangs. Any future tcp connection hangs in the same way (bytes sent but response never processed) on the tcp connection in the session until the session is closed on the server.
Server log at the moment this happens:
Client log at the same moment this happens:
Here is another interesting observation: when I added a 10 second keepalive to client and server, the server detects the hang and terminates the session after some time of hanging. TCP Reset received in Wireshark but client doesn't detect it. Client remains stuck.
I checked Wireshark and tcpdump on client and server at the same time. There is packets being received from client and server on both sides, so it is not ISP blocking.
This problem doesn't happen with shadowsocks alone or with goquiet.
I hope that helps to identify the problem. I hope this is solved, it is very annoying and prevents using of Cloak reliably.
@OneOfOne commented on GitHub (Dec 12, 2019):
To help debug this, try to trigger the bug, do
pkill -SIGABRT clientandpkill -SIGABRT serverand include the output in the bug report.@chenshaoju commented on GitHub (Dec 12, 2019):
Windows don't have
pkill.@notsure2 Please? 🙏
@notsure2 commented on GitHub (Dec 12, 2019):
@chenshaoju @OneOfOne @cbeuw
Here is the stack dumped by
kill -s SIGABRT $CLIENT_PIDduring the hang:@notsure2 commented on GitHub (Dec 12, 2019):
I'm not sure, but analyzing the code... I think it's a situation where deplex ends up in the path where it didn't find the stream ID because somehow it ended up running before OpenStream() was called... but I don't understand why it was waiting on the channel in session.go:203.
Anyway when it doesn't find the stream ID, it creates a new stream and writes the response packets to that instead of to the correct stream that is waiting for that reply... so the original correct stream hangs forever waiting for response.
It's confusing to me, but I'll try to confirm it with logging.
@OneOfOne commented on GitHub (Dec 12, 2019):
@notsure2 this feels like a race, any chance you can
go build -raceboth the client and server?@notsure2 commented on GitHub (Dec 13, 2019):
@OneOfOne I tried, but no race messages are emitted.
@chenshaoju I noticed a pattern. I made some changes in this branch https://github.com/notsure2/Cloak/tree/debug-stall to add more logging messages and now I noticed this log when the hang happens:
Server:
Client:
100% of the time when it hangs: this message is duplicated on the server:
But when it doesn't hang, this message doesn't repeat. I will try to add more messages or reach the root of this.
@notsure2 commented on GitHub (Dec 13, 2019):
@chenshaoju @cbeuw @OneOfOne
I have a theory on what's the problem. The problem is that the creation of the stream object representing a single client stream is mistakenly asynchronous relative to the reception of the first packet in it by the server, so it is possible for another packet to get received and mistakenly get assigned to a new stream object because the first packet in the stream finished processing before the stream object was added to the streams map by the other goroutine.
Here in this code:
In the case of the server, it will receive a packet for which there is no stream in the streams found, so it will make a new stream and then send it to acceptCh channel.
Who reads from this channel ? This code:
This method will be all the time sleeping waiting to receive a new stream from the acceptCh and then store it in the session streams map.
So the problem is that the first goroutine that put the stream in the channel resumes and gets called again for the next packet before
sesh.streams.Store(stream.id, stream)executes, so it gets mistakenly assigned to a new stream.The solution is to remove this channel and move the creation of streams to be directly in the path of packet processing instead of async by a separate goroutine.
I will test this and report back.
@notsure2 commented on GitHub (Dec 14, 2019):
@OneOfOne @cbeuw
I have made a pull request with a fix for this issue.
https://github.com/cbeuw/Cloak/pull/81/
@chenshaoju Please test this change, it should fix your problem.
@chenshaoju commented on GitHub (Dec 14, 2019):
@notsure2 Thank you, I have successfully built the server and client side. 👍
Test is running.
@cbeuw commented on GitHub (Dec 14, 2019):
@notsure2
Thank you very much for your work! My uni work was quite intense over the last month so sorry I couldn't chime in with the debugging.
The log you gave
was very helpful as this presents quite clearly a race situation. I'm fairly certain that your theory is correct:
Two frames of a new stream number arrives at the server at roughly the same time, which means that two recvDataFromRemote() invocations were called with these two frames at roughly the same time as well. One of the invocations will reach
streamI, existing := sesh.streams.Load(frame.StreamID)first, and start making a new stream instance. However, before this stream instance is stored in the map in Accept(), the other invocation will reachstreamI, existing := sesh.streams.Load(frame.StreamID)and start making a duplicate stream instance.I believe https://github.com/cbeuw/Cloak/pull/81 will vastly reduce the chance the race condition happens, as the stream instance is immediately stored into the map after its creation; however it doesn't completely fix it because as the first invocation is progressing from

streamI, existing := sesh.streams.Load(frame.StreamID), before it reachessesh.streams.Store(stream.id, stream), the second invocation could reachstreamI, existing := sesh.streams.Load(frame.StreamID), withexistingreturning false, and proceed with a duplicate stream instantiation.Like this:
Note that for this to happen, the two frames need to be processed on two separate goroutines. For this to happen, the two frames have to arrive on two separate TCP connections since the invocation of recvDataFromRemote() is not async in deplex(). This may never happen because at the moment, each stream is assigned one TCP connection and all frames of that stream sticks to the same connection; but this is not guaranteed by design as it depends on the frame-TCP connection distribution strategy, which may change in the future.
Nevertheless I will merge the pull request as it is a step forward. I'll try to think of a way to solve this race condition completely.
@notsure2 commented on GitHub (Dec 14, 2019):
At the moment I don't think there is any benefit at all of allowing different frames of the same stream of getting distributed over multiple tcp connections as they are produced sequentially at the source in the first place. If you allow this, you will also have to handle out of order delivery and reassembly and suddenly we are reinventing tcp again. There's no benefit I can see of doing this...
I've been running with this fix for 9 hours and the problem didn't resurface and I didn't need to restart Cloak even once.
Thanks for merging the fix :-)
@cbeuw commented on GitHub (Dec 14, 2019):
Actually this was the one of the first things I wrote when I started the project :P. Until a few months ago the strategy was to evenly distribute frames across all the connections, but then I realised that this is a bit unnecessary and I should've let TCP handle ordered delievery instead.
Besides, Cloak currently has (experimental) support for UDP based proxy protocols (it's preferable to use OpenVPN in UDP mode). In this case all frames are evenly spread across all TCP connections. Although ordered delivery is not needed, frames still need to be allocated to their correct streams to be sent to their correct UDP connections. This race condition may still happen.
@chenshaoju commented on GitHub (Dec 15, 2019):
After 24 hours test, This issue not happen again.
But somehow, the connection is a little unstable...Not sure is a network issue or not.
Log from server:
Log from client:
@notsure2 commented on GitHub (Dec 15, 2019):
@chenshaoju maybe try my tcp keepalive patch.
@chenshaoju commented on GitHub (Dec 17, 2019):
@notsure2 Thank you, I have successfully merge your code and build. 👍
The test is running.
@chenshaoju commented on GitHub (Dec 17, 2019):
Disconnect still happens, But I think it's a network issue.
When the disconnect happened, It's very difficult to connect SSH to the server at the same time.
After used @notsure2 TCP keepalive code, connection reliability has been improved, just a few seconds will rebuild the connection, no need waiting for a few minutes to rebuild the connection.
client.txt
server.txt
This issue will close after 24 hours, Thanks for everyone.
Cheers! 🍻