mirror of
https://github.com/ArchiveBox/ArchiveBox.git
synced 2026-04-25 09:06:02 +03:00
[GH-ISSUE #214] Archive Method: Chrome headless is not outputting expected files #3166
Labels
No labels
expected: maybe someday
expected: next release
expected: release after next
expected: unlikely unless contributed
good first ticket
help wanted
pull-request
scope: all users
scope: windows users
size: easy
size: hard
size: medium
size: medium
status: backlog
status: blocked
status: done
status: idea-phase
status: needs followup
status: wip
status: wontfix
touches: API/CLI/Spec
touches: configuration
touches: data/schema/architecture
touches: dependencies/packaging
touches: docs
touches: js
touches: views/replayers/html/css
why: correctness
why: functionality
why: performance
why: security
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/ArchiveBox#3166
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @fr0der1c on GitHub (Apr 10, 2019).
Original GitHub issue: https://github.com/ArchiveBox/ArchiveBox/issues/214
This is a really wired problem. I'm using ArchiveBox to archive a membership-based news website. Here is the result:
cookies.txtand addedCOOKIES_FILE=~/Downloads/cookies.txt. However, the result is still incomplete.CHROME_HEADLESS=Falseand from what I can see it's totally working fine. (using my profile and opening the page correctly 3 times)X-Frame-Options: SAMEORIGINon the original site. So I think it's not a problem that ArchiveBox can solve.It's pretty bad that none of the section is working.
update:
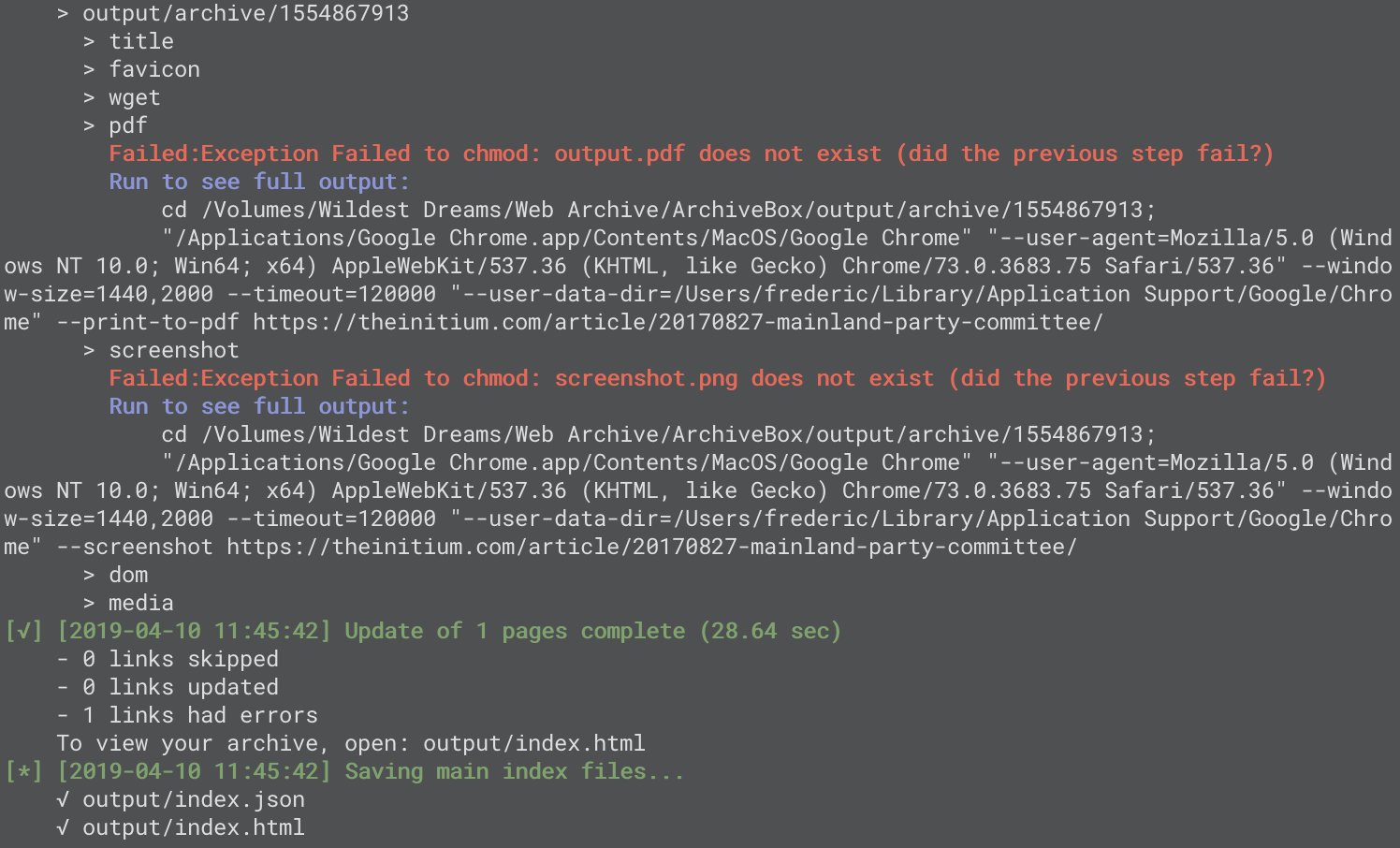
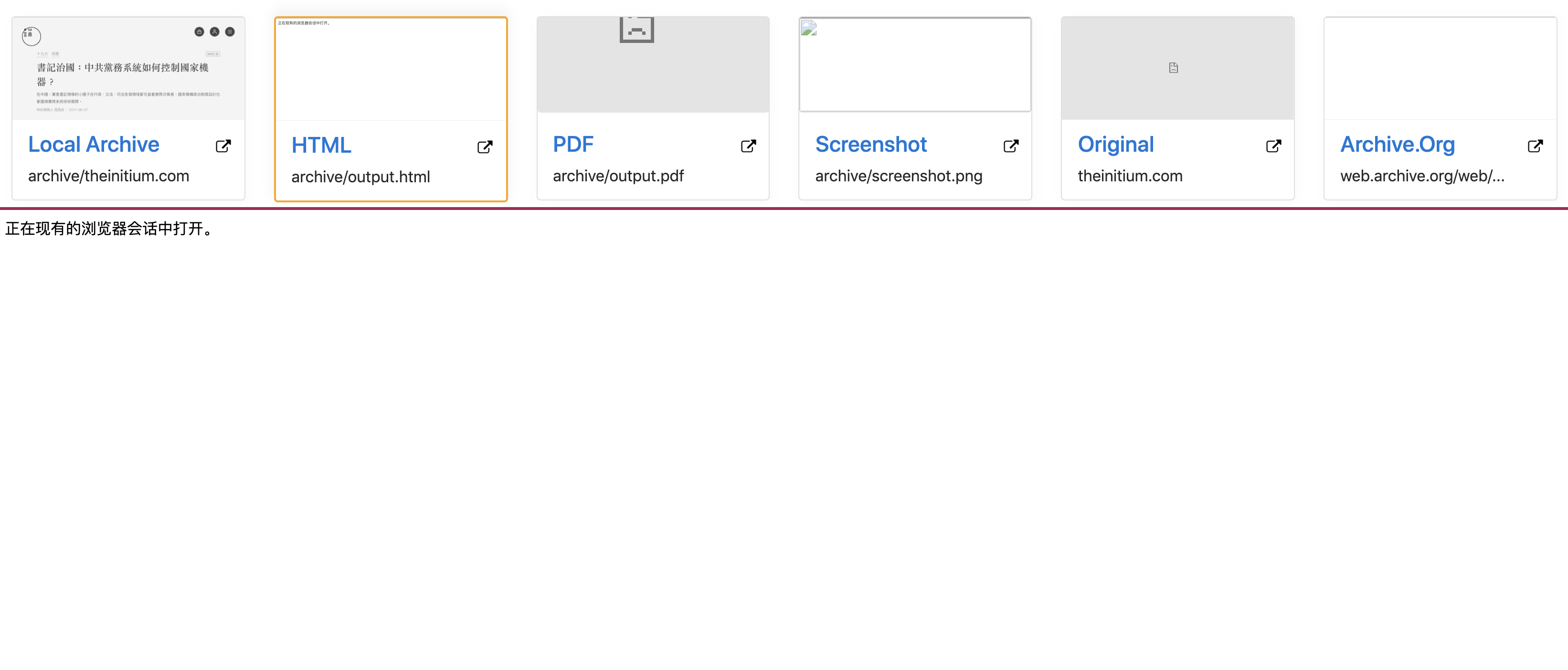
I tried a few times (delete output folder and re-run ArchiveBox). In the last few trials, the result becomes different.
There are some errors (
Exception Failed to chmod: screenshot.png does not exist) in the terminal even before the tab is opened and loaded in Chrome. As for the result, the PDF and screenshot become totally lost. And the "HTML" section becomes a blank page with an "opening in the current browser session" notice. This is really weird.update:
After some debugging, I found the cause:
wgetdefault user agent, the server treats this situation specially and response with part of the content even if there are session indicating you are a member. If you manually set the user agent to simulate a browser, you will get a 404 becauseAccess to fetch at 'https://api.theinitium.com/api/v1/channel/list/?language=zh-hant§ion=primary' from origin 'null' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.As for
wgetlocal archive, I guess there isn't much ArchiveBox can do. But I think ArchiveBox is able to fix the problem on HTML, PDF and screenshot and this is enough.@pirate commented on GitHub (Apr 10, 2019):
I'm going to close this since as you mentioned, wget will never be able to execute JS, and the HTML/PDF/Screenshot archive will be fixed by adding a delay option #213.
In the future we should be able to seamlessly archive sites like this since archiving will be done primarily via pywb + headless chrome instead of wget: #177.
@fr0der1c commented on GitHub (Apr 11, 2019):
Hi Nick,
There is another problem I mentioned:
Exception Failed to chmod: screenshot.png does not exist. From what I can see, this indicates that Chrome returned a 0 return code but the file is not generated. Do you have any idea why this is happening?On my computer, setting
CHROME_HEADLESS=Falsewill trigger this problem. I'm using Chrome 73.0.3683.86 on Mac.github.com/pirate/ArchiveBox@403025a73b/archivebox/archive_methods.py (L307-L320)@pirate commented on GitHub (Apr 16, 2019):
Does a chrome window open when you set
CHROME_HEADLESS=False? If so, do you notice any errors issues while it's attempting to screenshot?That error you're seeing means it failed to generate an output screenshot.png, which means the subsequent chmod fails due to the missing file.
@fr0der1c commented on GitHub (Apr 17, 2019):
Yes, a few Chrome tabs open when I set
CHROME_HEADLESS=False. Errors appear in the terminal when the page is loading.@pirate commented on GitHub (Apr 17, 2019):
What are the errors?
@fr0der1c commented on GitHub (Apr 18, 2019):
I run into

Failed:Exception Failed to chmod: output.pdf does not exist (did the previous step fail?)before the page is loaded. If I manually run to see full output, I get:@pirate commented on GitHub (Apr 23, 2019):
And when you ran that last screenshot command manually, was the
screenshot.pngfile produced? If not it's likely an issue with your chrome setup, if so then it's a bug with ArchiveBox and I'll investigate.@pirate commented on GitHub (Jul 24, 2020):
If you're still having this issue on the latest
djangobranch comment back and I'll reopen the ticket.